基本需求
有若干粤康码和行程卡的截图,要自动识别是否为当天提交的,粤康码是否绿码,行程卡是否带星
实现思路
整体的实现思路是:使用PaddleOCR的离线模型实现OCR识别功能,利用pywebio搭建一个简易的web服务,最后使用pyinstaller打包为windows可执行文件。
PaddleOCR的离线模型使用的是RapidOCR的实现:https://github.com/RapidAI/RapidOCR,在一开始我想用Paddle官方的Paddlehub工具在服务器上部署一个PaddleOCR工具,但是发现批量识别的时候对服务器内存开销太大了。
首先将RapidOCR项目下python/onnxruntime_infer目录下载到本地
下载相应模型和用于显示的字体文件
下载之后模型和相应字体文件放在fonts和models下,最终目录结构如下:
models
|-- ch_PP-OCRv2_det_infer.onnx
|-- ch_ppocr_mobile_v2.0_cls_infer.onnx
|-- ch_ppocr_mobile_v2.0_det_infer.onnx
|-- ch_ppocr_server_v2.0_det_infer.onnx
|-- ch_ppocr_server_v2.0_rec_infer.onnx
|-- en_number_mobile_v2.0_rec_infer.onnx
|-- korean_mobile_v2.0_rec_infer.onnx
`-- japan_rec_crnn.onnx
fonts
|-- msyh.ttc
`-- korean.ttf随后编写PyWebIO的脚本
from pywebio.input import input, FLOAT, file_upload from pywebio.output import put_text, put_image, put_row, put_scope, put_info, put_processbar,set_processbar from pywebio import start_server from rapid_ocr_api import TextSystem, visualize from PIL import Image from io import BytesIO import time from datetime import date def ocr(image_path): det_model_path = 'models/ch_ppocr_mobile_v2.0_det_infer.onnx' cls_model_path = 'models/ch_ppocr_mobile_v2.0_cls_infer.onnx' # 中英文识别 rec_model_path = 'models/ch_ppocr_mobile_v2.0_rec_infer.onnx' keys_path = 'rec_dict/ppocr_keys_v1.txt' text_sys = TextSystem(det_model_path, rec_model_path, use_angle_cls=True, cls_model_path=cls_model_path, keys_path=keys_path) dt_boxes, rec_res = text_sys(image_path) return rec_res def check(rec_res,img): """ 检查识别到的内容 """ # 所有词语形成一个词典 word_list = [] for i in rec_res: word_list.append(i[0]) # 拼接为一串字符串 words = ''.join(word_list) # 保存文件名,系统导出文件名即为用户名 filename = img['filename'] #判断图片是粤康码还是行程卡 if '粤康码' in words: flag = 'yuekangma' else: flag = 'xingchengka' # 粤康码监测日期与绿码 if flag == 'yuekangma': # 监测粤康码日期 # 粤康码日期是04-20的格式 today = date.today().strftime("%m-%d") # today = '04-21' is_today = False is_green = False if today in words: is_today = True if '绿码' in words: is_green = True if not is_today: put_text(filename,'粤康码信息可能不是今日,请复查') put_image(img['content']) if not is_green: put_text(filename,'粤康码信息可能不为绿码,请复查') put_image(img['content']) # 行程卡判别 if flag == 'xingchengka': today = date.today().strftime("%m.%d") # today = '04.21' is_today = False is_star = False if today in words: is_today = True if '中高风险地区' in words: is_star = True if not is_today: put_text(filename,'行程卡信息可能不是今日,请复查') put_image(img['content']) if is_star: put_text(filename,'行程卡信息可能带星,请复查') put_image(img['content']) def main(): file_path = 'test_images/{}.png'.format(time.time()) put_info('Powered by Hsinyan') put_info("请批量选中粤康码和行程卡上传,系统会自动检查是否符合") imgs = file_upload("Select some pictures:", accept="image/*", multiple=True) count,total = 0, len(imgs) put_text('检测中,共{}张'.format(total)) put_processbar('bar') for img in imgs: # 显示进度条 set_processbar('bar', count / total) count +=1 put_text() image = Image.open(BytesIO(img['content'])) image.save(file_path) rec_res = ocr(file_path) # put_image(image) check(rec_res,img) set_processbar('bar', 1) put_text('检测完毕!') if __name__ == '__main__': start_server(main,8866)此处将PaddleOCR识别出的字符拼接为一个,然后根据关键词检验是否为今日的记录。
比如:粤康码的日期格式为「04-20」,则可以按照此在字符串中匹配子串,同理匹配「绿码」关键字可以确定是否为绿码
在行程卡检验中,日期格式为「04.20」,当行程卡带星时,会有中高风险地区提升,则匹配「中高风险」字符串即可。
然后建议新建一个虚拟环境,使用pyinstaller打包安装
相关命令如下
pyi-makespec -c web_service.py随后修改生成的web_service.spec文件,如下
# -*- mode: python ; coding: utf-8 -*- from pywebio.utils import pyinstaller_datas .... a = Analysis( ... datas=pyinstaller_datas(), ... )然后打包生成
pyinstaller web_service.py会在dist文件夹下生成一个可执行文件
随后把相关资源文件夹复制到可执行文件(exe)的同级目录下
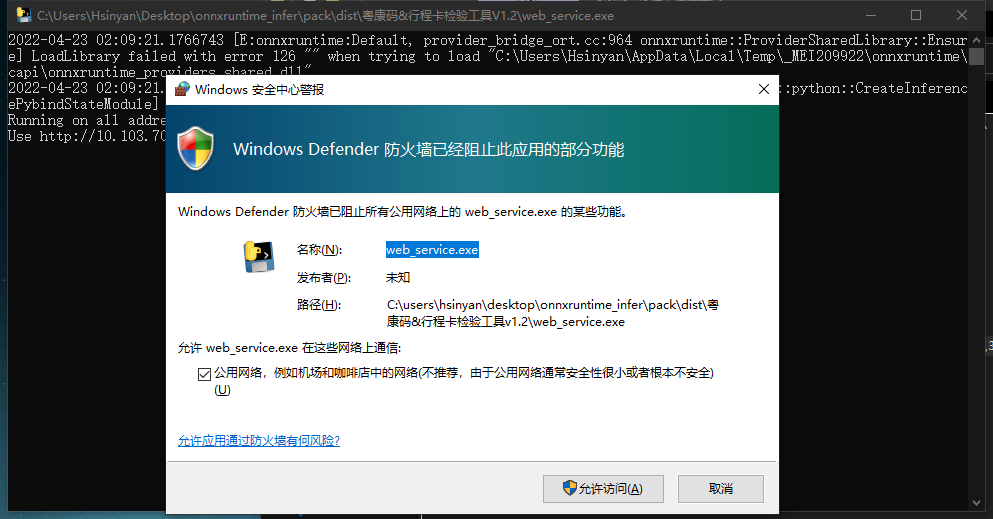
可能会弹出相关警告,同意即可
访问localhost:8866,批量上传图片耐心等待检验即可,若图片有问题时,系统会弹出来,进行复核就行了。
未来工作
- 显示使用耗时
- 优化字符串匹配的算法,提高识别效率

1 条评论
作者的观点新颖且实用,让人在阅读中获得了新的思考和灵感。